'23.3.6(월) 딥러닝을 이용한 자연어처리 <3: Counter Based Word Representation>
■ 자연어처리에서 텍스트를 표현하는 방법으로는 여러가지가 있음.
그 중에서도 검색과 텍스트 마이닝 분야에서 주로 사용되는 카운트 기반의 텍스트 표현 방법인
Document Term Matric (DTM)과 Term Frequency-Inverse Document Frequency(TF-IDF)를 학습하고자 함.
■ 텍스트를 수치화하게 되면 어떤 단어가 특정 문서 내에서 얼마나 중요한지 (1) 문서의 핵심어 추출(2)
검색 엔진에서의 검색 결과 순위 결정(3) 문서들 간의 유사도 측정(4) 등의 용도로 사용 가능
■ 단어를 표현하는 방법은 Local Representation(국소 표현) 방법과 Distributed Representation(분산 표현)
방법이 있음. *local == discrete(이산), distributed == continuous(연속) 이라고도 함
■ local representation 방법은 puppy, cute, lovely라는 단어가 있을 때 각 단어에 1번, 2번, 3번 등과
같은 숫자를 mapping하여 부여하는 것. 즉, 단어의 빈도수를 count하여 수치화 하는 방법
■ distributed representation 방법은 puppy라는 단어 근처에 주로 cute, lovely이라는 단어가
자주 등장하므로, puppy라는 단어는 cute, lovely와 유사한 단어를 정의할 수 있음.
즉, 단어의 의미 및 뉘앙스를 표현 가능함
■ Local Representation 의 예시 : Bag of Words와 그의 확장인 DTM(또는 TDM)과 TF-IDF가 있음
Distributed Representation 의 예시 : Wrod2Vec와 그의 확장인 FastText가 있음.
두 가지 방법이 모두 사용된 예시 : Glove가 있음
1. Bag of Words (BoW)
- 단어의 등장 순서를 고려하지 않는 빈도수(frequency) 기반의 단어 표현 방법
※ 영어 단어 그대로 가방안에 단어들을 전부 넣고 가방을 흔들어 단어들을 섞는 것이기에
단어의 순서는 중요하지 않음
2. Document-Term Matrix, DTM (문서 단어 행렬)
- 서로 다른 문서들의 BoW들을 결합한 표현 방법으로 다수의 문서에서 등장하는
각 단어들의 빈도를 행렬로 표현한 것
문서1 : 먹고 싶은 사과
문서2 : 먹고 싶은 바나나
문서3 : 길고 노란 바나나 바나나
문서4 : 저는 과일이 좋아요
예를 들어 위와 같은 4개의 문서를 띄어쓰기 단위 토큰화를 수행하고, DTM으로 표현하면 아래와 같음
| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 | |
| 문서1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 문서2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 문서3 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| 문서4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
- DTM의 한계
. (1) Sparese Representation (희소 표현)
one-hot-vector 및 DTM는 단어 집합의 크기가 벡터의 차원이 되고 대부분의 값이 0이 되는 벡터로
공간적 낭비와 계산 리소스를 증가시킬 수 있음. 대부분의 값이 0인 표현을 Spare Vector(희소 벡터) 또는
Spare Matrix(희소 행렬)라고 부르는데 spare vector는 많의 양의 저장 공간과 높은 계산 복잡도를 요구함
따라서, 전처리를 통해 단어 집합의 크기를 줄이는 것이 중요함
. (2) 단어 빈도 수 기반 접근의 한계 발생
예를 들어 the는 어떤 문서이든 자주 등장하는데, 문서1 문서2 문서3에서 동일하게 the의 빈도수가
높다고 해서 이 문서들이 서로 유사한 문서라고 판단하면 안됨. 따라서 각 문서에서는 중요한 단어와
불필요한 단어들이 혼재되어 있기에 단어마다 가중치를 주는 TF-IDF 방법이 나옴
3. TF-IDF(Term Frequenct-Inverse Document Frequency)
- DTM 內 각 단어에 대한 중요도를 계산할 수 있음.
- TF-IDF는 TF(특정 문서 D에서의 특정 단어 T의 등장 횟수) * IDF 임
. DF(특정 단어 T가 등장하는 문서의 수) 이고 IDF의 표현은 아래와 같음 만약 IDF를
역수({n}/{df(t)}라는 식)로 사용한다면 총 문서의 수 n이 커질 수록, IDF의 값은 기하급수적으로 커지게 됨.
그렇기 때문에 log를 사용함
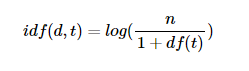
- TF-IDF 값이 낮으면 중요도가 낮은 것이며, 값이 크면 중요도가 큰 것임. 즉, the나 a와 같은 불용어의 경우
모든 문서에서 자주 등장하기에 값이 매우 낮음
참조 링크 : https://wikidocs.net/24557
04. 카운트 기반의 단어 표현(Count based word Representation)
자연어 처리에서 텍스트를 표현하는 방법으로는 여러가지 방법이 있습니다. 이번 챕터에서는 그 중 정보 검색과 텍스트 마이닝 분야에서 주로 사용되는 카운트 기반의 텍스트 표현 방법인…
wikidocs.net